


记得关注+转发哟

开发语言:Python2.7
开发环境:64位Windows8系统,4G内存,i7-3612QM处理器。
数据库:MongoDB 3.2.0
(Python编辑器:Pycharm 5.0.4;MongoDB管理工具:MongoBooster 1.1.1)
多线程使用 multiprocessing.dummy 。
抓取 Cookie 使用 selenium 和 PhantomJS 。
判重使用 BitVector 。
启动前配置:
MongoDB安装好 能启动即可,不需要配置。
Python需要安装以下模块(注意官方提供的模块是针对win32系统的,64位系统用户在使用某些模块的时候可能会出现问题,所以尽量先找64位模块,如果没有64的话再去安装32的资源):
requests、BeautifulSoup、multiprocessing、selenium、itertools、BitVector、pymongo

启动程序:
-
进入 myQQ.txt 写入QQ账号和密码(用一个空格隔开,不同QQ换行输入),一般你开启几个QQ爬虫线程,就至少需要两倍数量的QQ用来登录,至少要轮着登录嘛。
-
进入 init_messages.py 进行爬虫参数的配置,例如线程数量的多少、设置爬哪个时间段的日志,哪个时间段的说说,爬多少个说说备份一次等等。
-
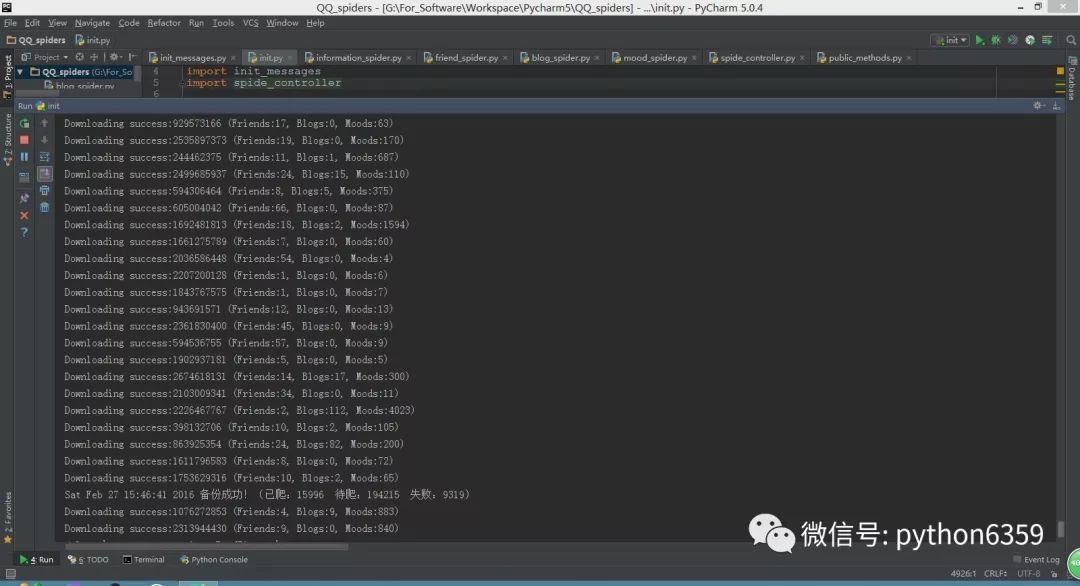
运行 init.py 文件开启爬虫项目。
-
爬虫开始之后首先根据 myQQ.txt 里面的QQ去获取 Cookie(以后登录的时候直接用已有的Cookie,就不需要每次都去拿Cookie了,遇到Cookie失效也会自动作相应的处理)。获取完Cookie后爬虫程序会去申请四百多兆的内存,申请的时候会占用两G左右的内存,大约五秒能完成申请,之后会掉回四百多M。
-
爬虫程序可以中途停止,下次可打开继续抓取。
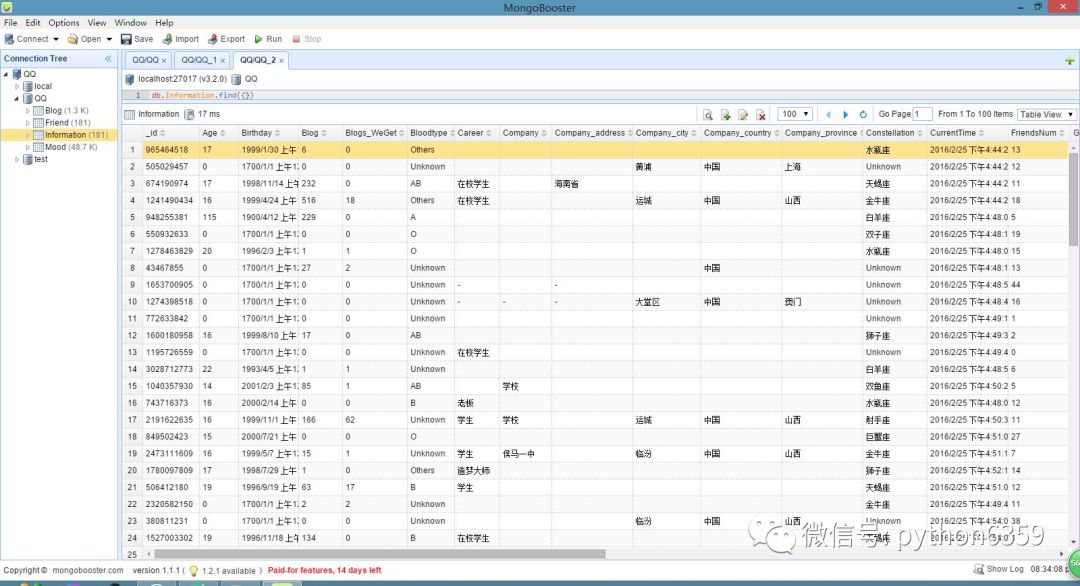
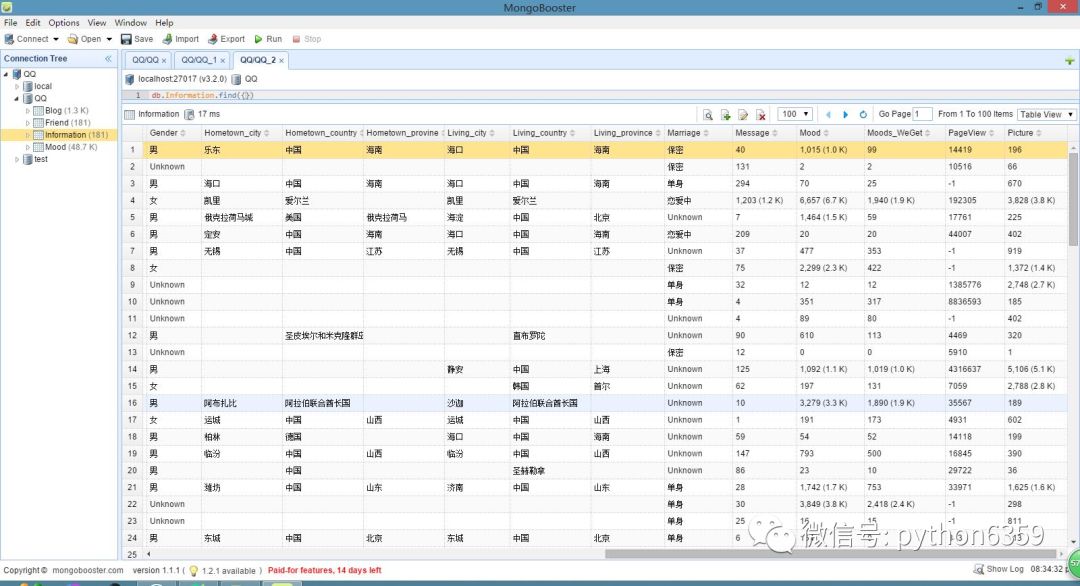
?按住图片左右滑动
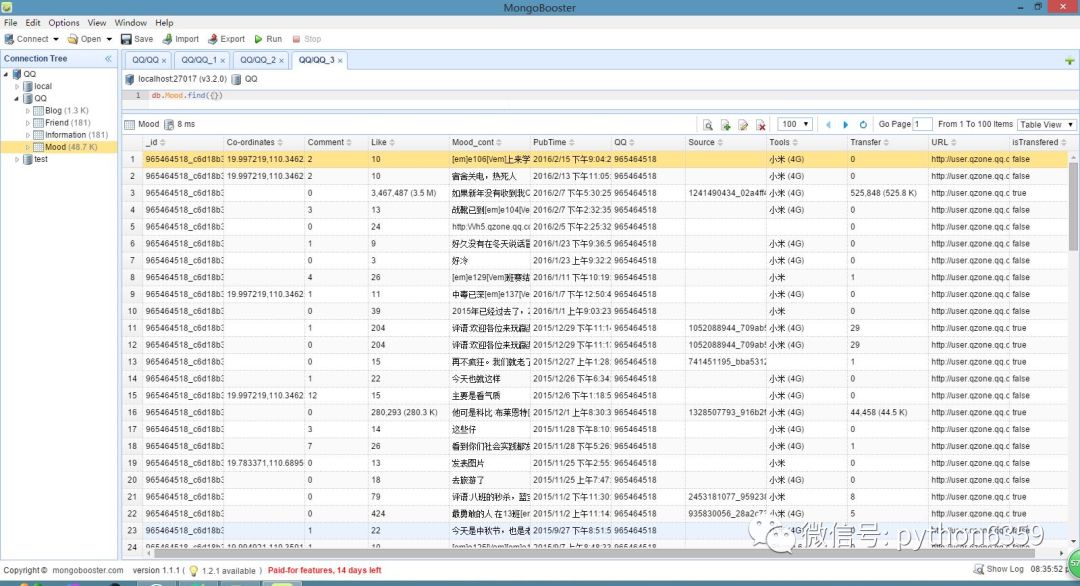
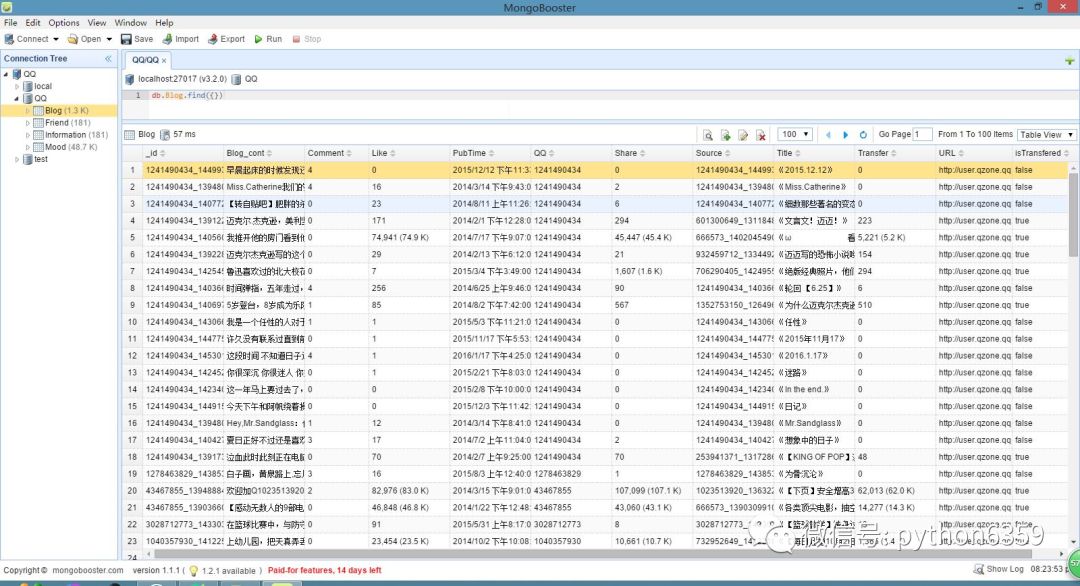
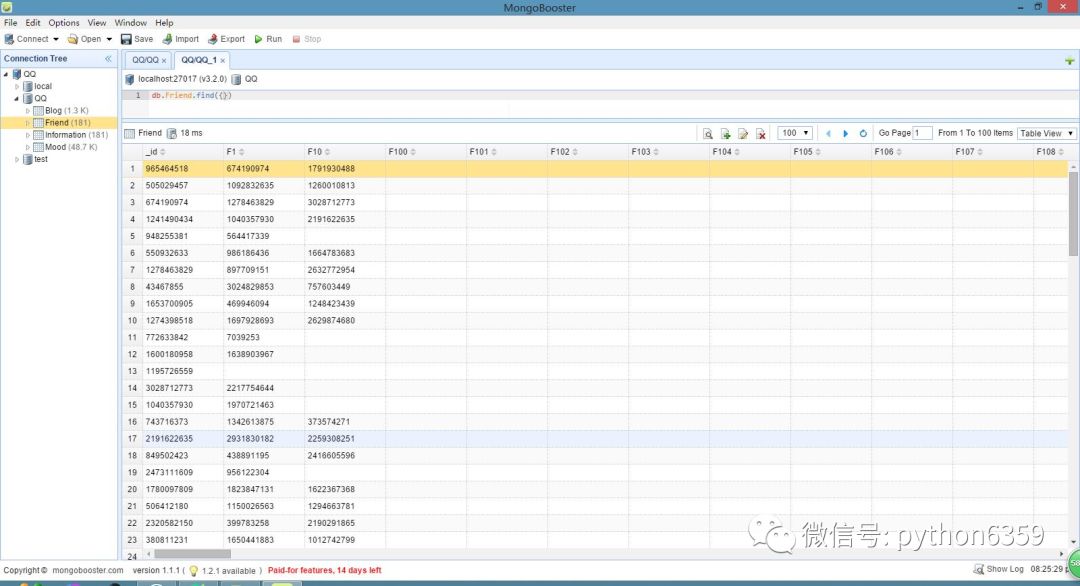
数据库说明


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。