
当一张表的数据量达到上百万条记录时,单台MySQL数据库采用传统的单表方式就很有可能无法满足业务的性能需求。解决这种性能问题的技术方案很多,包括分表、分库或搭建MySQL集群,每种技术方案又分别有若干种实现方式。本文将通过实例描述如何使用MERGE存储引擎实现MySQL的分表机制,不会涉及其他的技术方案或实现方式。
一、建立数据库
创建名为test_myisam_db的数据库,执行以下SQL:
-- 创建数据库 CREATE SCHEMA `test_myisam_db` DEFAULT CHARACTER SET utf8 ;
二、建立分表
分表必须使用MyISAM存储引擎,而MyISAM表的数据文件(.MYD文件)和索引文件(.MYI文件)是可以分散在不同的磁盘或目录上存储的。
在Shell中执行以下命令,创建存储子表数据和索引的目录:
# 创建存储user1表数据和索引的目录 mkdir -p /home/user1 chown -R mysql:mysql /home/user1 # 创建存储user2表数据和索引的目录 mkdir -p /home/user2 chown -R mysql:mysql /home/user2 # 创建存储user3表数据和索引的目录 mkdir -p /home/user3 chown -R mysql:mysql /home/user3
启用MySQL的have_symlink选项,使得MySQL支持符号链接,否则就不能指定MyISAM表的数据文件和索引文件的存储路径。在Shell中执行以下命令,编辑my.cnf文件:
vi /usr/local/MySQL/etc/my.cnf
在my.cnf文件的[mysqld]分段中添加:
symbolic-links
保存my.cnf文件之后,重新启动mysql服务:
service mysql restart
创建user1、user2、user3分表,执行以下SQL:
-- 创建user1子表 CREATE TABLE `test_myisam_db`.`user1` ( `id` INT NOT NULL, `user_name` VARCHAR(45) NOT NULL, `password` VARCHAR(45) NOT NULL, `create_time` TIMESTAMP NULL, `update_time` TIMESTAMP NULL, PRIMARY KEY (`id`), UNIQUE INDEX `user_name_UNIQUE` (`user_name` ASC)) ENGINE = MyISAM DATA DIRECTORY = '/home/user1' INDEX DIRECTORY = '/home/user1'; -- 创建user2子表 CREATE TABLE `test_myisam_db`.`user2` ( `id` INT NOT NULL, `user_name` VARCHAR(45) NOT NULL, `password` VARCHAR(45) NOT NULL, `create_time` TIMESTAMP NULL, `update_time` TIMESTAMP NULL, PRIMARY KEY (`id`), UNIQUE INDEX `user_name_UNIQUE` (`user_name` ASC)) ENGINE = MyISAM DATA DIRECTORY = '/home/user2' INDEX DIRECTORY = '/home/user2'; -- 创建user3子表 CREATE TABLE `test_myisam_db`.`user3` ( `id` INT NOT NULL, `user_name` VARCHAR(45) NOT NULL, `password` VARCHAR(45) NOT NULL, `create_time` TIMESTAMP NULL, `update_time` TIMESTAMP NULL, PRIMARY KEY (`id`), UNIQUE INDEX `user_name_UNIQUE` (`user_name` ASC)) ENGINE = MyISAM DATA DIRECTORY = '/home/user3' INDEX DIRECTORY = '/home/user3';
注意
- 分表的id不能是自增(auto increment)的;
- 分表必须使用MyISAM存储引擎;
- 每个分表的表结构必须相同;
- MySQL必须具有存储分表数据文件和索引文件的目录的读写权限;
-
必须启用MySQL的符号链接支持功能。
上述操作完成之后,检查分表是否正确创建。以user1分表为例,在Shell中执行以下命令,检查分表的数据文件和索引文件是否正确创建:
ll /home/user1
若命令输出信息如下图所示,则表示分表的数据文件和索引文件创建成功:

在Shell中执行以下命令,检查MySQL是否为分表的数据文件和索引文件正确创建软链接:
ll /var/lib/mysql/test_myisam_db
若命令输出信息如下图所示,则表示软链接创建成功:
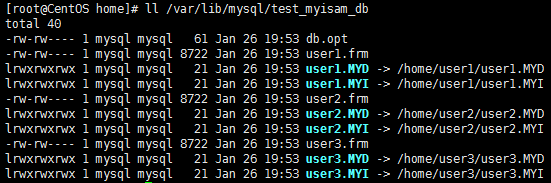
注意
- MYD文件是MyISAM表的数据文件;
- MYI文件是MyISAM表的索引文件;
- frm文件用于存储MyISAM表的表结构。
三、建立总表
总表必须使用**MRG_MyISAM**存储引擎,总表本身不存储任何数据,一般用于查询分表的数据,相当于是各个分表的一层外壳。执行以下SQL,创建总表:
-- 创建alluser总表 CREATE TABLE `test_myisam_db`.`alluser` ( `id` INT NOT NULL, `user_name` VARCHAR(45) NOT NULL, `password` VARCHAR(45) NOT NULL, `create_time` TIMESTAMP NULL, `update_time` TIMESTAMP NULL, PRIMARY KEY (`id`), UNIQUE INDEX `user_name_UNIQUE` (`user_name` ASC)) ENGINE = MRG_MyISAM UNION = (`user1`,`user2`,`user3`);
注意
- 总表的表结构必须与各个分表相同;
- 总表必须使用MRG_MyISAM存储引擎;
- 总表不会创建任何数据文件和索引文件;
通常,总表的INSERT_METHOD应当配置为NO,或者不配置。INSERT_METHOD指明插入方式,取值可以是:0 不允许插入;FIRST 插入到UNION中的第一个表; LAST 插入到UNION中的最后一个表。
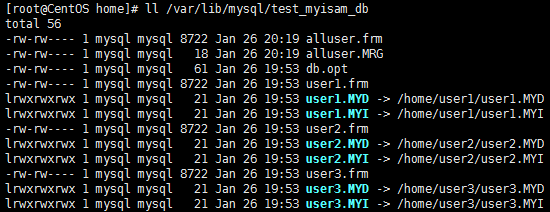
在Shell中执行以下命令,检查总表是否成功创建:
ll /var/lib/mysql/test_myisam_db
若命令输出信息如下图所示,则表示总表创建成功:
在Shell中执行以下命令,检查总表是否成功关联子表:
cat /var/lib/mysql/test_myisam_db/alluser.MRG
若命令输出信息如下图所示,则表示总表成功关联子表:

注意
- MRG文件存储总表需要映射的子表的表名;
- 总表本身不存储任何数据和索引;
- INSERT_METHOD需要设置为NO,或者不配置;
- 总表的id不能是自增(auto increment)的。
五、如何操作MERGE表的数据
插入(INSERT)数据时,需要根据给定的路由策略将新数据分别插入不同的子表,此处采用对id进行模3计算(可能结果为0、1、2)来决定插入哪个子表。
首先,应当获取id,这个id应当在各个子表中都是唯一的,我们需要一张表来专门创建id,执行如下SQL语句:
CREATE TABLE `test_myisam_db`.`create_id` ( `id` INT NOT NULL, PRIMARY KEY (`id`)) ENGINE = MyISAM;
当需要插入数据时,必须由这个表来产生id值,PHP示例代码如下所示:
/**
* 获取唯一的id
*/
function get_AI_ID() {
$sql = "insert into create_id (id) values('')";
$this->db->query($sql);
return $this->db->insertID();
}
插入一条新数据的PHP代码如下所示:
/**
* 插入一条新数据
*/
function new_Article() {
$id = $this->get_AI_ID();
$table_name = $this->get_Table_Name($id);
$sql = "INSERT INTO {$table_name} (id, user_name, password, create_time, update_time) VALUES ('{$id}', 'ghoulich', 'password', '2016-01-01 00:00:00', '2016-01-01 00:00:00')";
$this->db->query($sql);
}
/**
* 根据id获取表名
*/
function get_Table_Name($id) {
return 'user'.intval($id)%3+1;
}
其他的删除(DELETE)、查询(SELECT)、修改(UPDATE)、清空(TRUNCATE)等操作都可以通过总表alluser完成。
基于MERGE存储引擎实现的分表机制,比较适用于插入和查询频率较高的场景。由于MyISAM具有表级别的锁机制,所以不适用于更新频率较高的场景。
六、MERGE分表的优点
MERGE分表可以解决下面的问题:
- 适用于存储日志数据。例如,可以将不同月份的数据存入不同的表,然后使用myisampack工具压缩数据,最后通过一张MERGE表来查询这些数据。
- 可以获得更快的速度。可以根据某种指标,将一张只读的大表分割成若干张小表,然后将这些小表分别放在不同的磁盘上存储。当需要读取数据时,MERGE表可以将这些小表的数据组织起来,就好像使用先前的大表一样,但是速度会快很多。
- 可以提高搜索效率。可以根据某种指标将一张只读的大数据表分割为若干个小表,然后根据不同的查询维度,可以得到若干种小表的组合,然后再为这些组合分别创建不同的MERGE表。例如,有一张只读的大数据表T,分割为T1、T2、T3、T4,共4张小表,有两种查询维度A和B,A可以得到小表组合T1、T2和T3,B可以得到小表组合T2、T3和T4,分别为A和B创建两个MERGE表,也就是M1和M2,这两个MERGE表分别关联的小表是存在交叠的。
- 可以更加有效的修复表。修复单个的小表要比修复大数据表更加容易。
- 多个子表映射至一个总表的速度极快。因为MERGE表本身不会存储和维护任何索引,索引都是由各个关联的子表存储和维护的,所以创建和重新映射MERGE表的速度非常快。
- 不受操作系统的文件大小限制。单个表会受到文件大小的限制,但是拆分成多个表,则可以无限扩容。
- MERGE表还可以用来给单个表创建别名,并且几乎不会影响性能。
七、MERGE分表的问题
- 总表(MERGE表)必须使用MRG_MyISAM存储引擎,子表必须使用MyISAM存储引擎,不可避免会受到MyISAM存储引擎的限制。
- MERGE表不能使用某些MyISAM特性。例如,虽然可以为子表创建全文索引,但是却不能使用全文索引,通过MERGE表查询数据。
- MERGE表会使用更多的文件描述符。如果有10个客户端使用1张MERGE表,那么就需要消耗(10×10)+10个文件描述符(其中,10个客户端分别有10个数据文件描述符,并且会共享使用10个索引文件描述符)。
- 若使用
ALTER TABLE语句修改总表的存储引擎,那么会立即丢失总表和子表的映射关系,并且会将所有子表的数据拷贝至修改后的新表。 - 总表和子表的主键都不能使用自动增长(auto increment)。
- 子表之间不能保证唯一键约束,只能保证单个子表内部的唯一性约束。
- 由于不能保证唯一键约束,导致
REPLACE语句的行为会不可预期,INSERT ... ON DUPLICATE KEY UPDATE语句也有类似问题。因此,只能使用路由策略,对子表使用这些语句,而不能对总表使用。 - 子表不支持分区(Partition)。
- 当正在使用总表时,不能对任何子表执行
ANALYZE TABLE、REPAIR TABLE、OPTIMIZE TABLE、ALTER TABLE、DROP TABLE、DELETE或TRUNCATE TABLE语句,否则会导致不可预期的结果。 - 总表和子表的表结构必须完全一致。
- 总表可以映射的所有子表的总行数上限为 264 行。
- 不支持
INSERT DELAYED语句。